Как потомки участников войны могут отследить боевой путь своих предков? В послевоенные годы в архивах страны накопилось множество документов о судьбе, боевом пути и назначениях людей, участвовавших в войне. Оцифровка этих документов - долгий и трудоемкий процесс, ускорить которой возможно благодаря технологии распознавания текста – OCR.
Как это работает
Как и многие другие задачи в компьютерном зрении распознавание текста на картинках состоит из двух этапов:
- Поиск текста на изображении.
- Разпознавание букв, цифр и символов, найденных на первом этапе.
В качестве примера возьмем такое изображение

Поиск текста на изображении
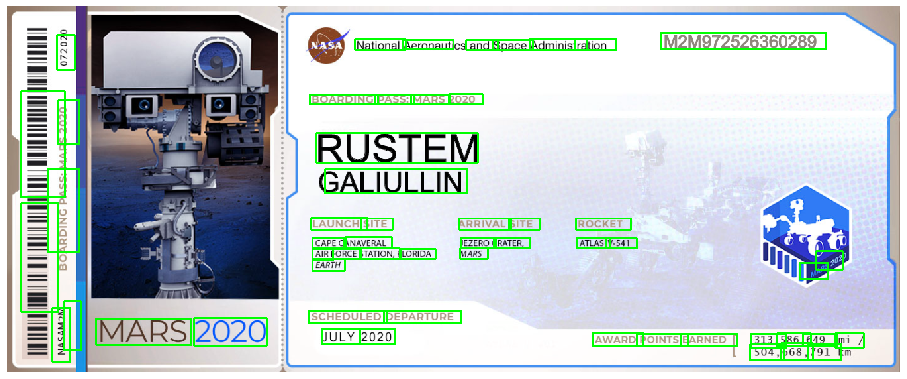
С использованием открытого детектора текста нам удалось найти 55 текстовых областей. Причем заметно, что горизонтальный текст благодаря более точным прямоугольникам обнаруживается лучше вне зависимости от размера и шрифта. При этом пробелы после слов на первой строке попали в разные прямоугольники.
Распознавание обнаруженного текста

Если текст ровный (“BOADRDING”, “MARS”, “2020”) и четко видны буквы и цифры, алгоритму tesseract-ocr легко удается правильно определить текст. Хорошая точность достигается за счет рекуррентных нейросетей, которые лучше справляются с последовательностью данных.
Однако, если возникает какой-либо шум, как в примерах (“STATION”, “SCHEDULED”), то в результате добавляются ненужные символы. На последних двух изображениях не удается определить текст. Это пример того, как ошибки первого этапа поиска текста влияют на его распознавание.
Адаптация OCR под вашу задачу
Учитывая возможность использовать открытые алгоритмы, для достижения наивысшей точности целесообразно обучить нейронные сети для работы с собственным набором данных. Обучение алгоритмов также происходит в два этапа: детекция текста и распознавание.
В процессе обучения потребуется большое количество размеченных данных. Это может быть затратно для небольших и средних компаний, поэтому возможно комбинировать собственный массив текстовых изображений с открытыми наборами данных. Нередко для увеличения обучающей выборки разработчики самостоятельно синтезируют данные.
При обучении собственного алгоритма нужно учитывать целевое применение. Если алгоритм должен работать на мобильных устройствах или в режиме реального времени, целесообразно выбрать легковесные модели. Если изображения содержат немного текста, то для увеличения скорости обработки можно объединить детекцию и распознавание в единую модель.

При обучении нейронных сетей под собственную задачу вы сможете достичь такого же результата, как на изображении выше. Алгоритмы достаточно хорошо находят текст и оцифровывают его. Причем алгоритм распознает только целевой текст. Затем система правильно классифицирует такие схожие сущности как имя и фамилия, серия и номер, и т.д. Высокое качество достигается за счет обработки сразу нескольких последовательных кадров, что позволяет снизить уровень шума.
Рукописный текст
Иная ситуация с разпознаванием рукописного текста. На данный момент нет универсальных алгоритмов, которые могли бы применяться для любого рукописного текста хотя бы на одном языке. Проблема решается посегментно - в большинстве случаев компании могут решать узкие задачи благодаря оцифровке рукописного текста.
Оцифровка рукописного текста с помощью открытых алгоритмов
 |
 |
Несмотря на то, что алгоритмы способны определить рукописный текст, полнота распознавания заметно ниже в сравнении с печатным. Однако на примере распознавания найденного текста, мы видим, что даже легкие слова как (“and”, “neat”) распознаются неверно. При этом даже длина слова определяется ошибочно. Единственный выход - обучать нейронные сети, заточенные под конкретный формат и топологию текста.
Применение OCR
OCR активно развивается. Это обусловлено широким спектром кейсов практического применения этой технологии.
Вот лишь некоторые из них:
- распознавание данных с документов, как персональных (паспорт, ИНН и т.д.), так и деловых (акты, счета, накладные и т.д.)
- оцифровка бумажных документов и архивов
- распознавание автомобильных номерных знаков
- мгновенный фото-переводчик
- распозавание данных с банковской карты для быстрого перевода денег
Технология OCR может применяться в любой деятельности, где необходимо создать альтернативу ручному вводу данных для снижения трудоемкости, процента ошибок или увеличения скорости обработки данных. Еще одна цель развертывания OCR - сбор данных. Например, нанесение адресов жилых домов на карты с использованием данных уличной фотосъемки.
Пример детекции и распознавания текста (Счет на оплату)
 |
 |
Как видим на изображении слева – детекция с помощью открытых алгоритмов показывает среднее качество: прямоугольники хорошо покрывают текст на изображении, однако между ними есть много пересечений. На изображении справа, восстановленном после распознавания найденного текста, отчетливо понятно: такой алгоритм нельзя применить в промышленном масштабе. Иначе придется иметь дело с большим количеством неточностей. К счастью, такие проблемы решаются достаточно легко с помощью обучения собственных нейросетевых алгоритмов.
Сложности реализации
При реализации проектов по распозанаванию текста на картинках возникает немало сложностей. Они могут возникнуть на разных этапах и решаться совершенно различными методами.
- Шум во входных данных. Как и в любых других проектах, связанных с компьютерным зрением, на качество распознавания влияет качество съемки. Смазанность текста, блики на глянцевых документах или плохое освещение неминуемо приведут к потере данных. Для борьбы с таким шумом необходимо мотивировать пользователя минимизировать низкокачественные фото на этапе съемки.
- Топология текста. Если для человека не составляет труда разделить слова пробелами или разбить параграф на разные строки, то для алгоритмов это представляет дополнительную сложность. Целесообразнее уже на этапе разметки данных понимать, каким образом будет применяться модель. Далее необходимо создать аннотацию, которая при необходимости будет отражать разные строки и слова. Также возможно, хотя это менее эффективно, применить классические методы компьютерного зрения по отделению фона от полезной информации.
- Очистка полученного текста. Как видно на примерах выше, мы не всегда получаем точный результат. Поэтому выходные данные от нейронных сетей можно и нужно дополнительно обрабатывать. Это поможет устранить известные нам “косяки”. Здесь чаще всего применяются методы обработки естесственного языка. Такие как устойчивые выражения, заданные словари или именованные сущности.
Вместо заключения
Для решения конкретной проблемы логично делать поступательные шаги и с каждым новым шагом улучшать результаты. Например, для внедрения OCR можно последовательно пройти несколько этапов:
- Подготовить небольшие тестовые данные из собственных источников для валидации алгоритмов. На основе этих данных визуально выбрать лучший алгоритм и с его помощью определять точность.
- Протестировать открытые алгоритмы на тестовом множестве из этапа 1. Цель - понять потенциал применения OCR к этим данным.
- Обучить нейронные сети на открытых данных, наиболее приближенных к собственным. Цель - разработать первый прототип для развертывания и тестирования внутри.
- Собрать собственный набор данных и разметить его. Цель - получить объемную обучающую и тестовую выборки для дальнейшей количественной оценки новых алгоритмов.
- Обучить нейронные сети (сверточные / сверточные + рекуррентные) на собственном наборе данных. Цель - создать модели для промышленного применения с максимальной точностью и скоростью работы.