Если количество и конверсия посетителей сайтов или онлайн-магазинов измеряется достаточно просто, то клиентская аналитика традиционных точек продаж – непростой процесс. К примеру, мы хотим посчитать всех людей, посетивших магазин в течение дня, но не совершивших покупки. Как это сделать?
В этой статье расскажу о системе подсчета количества уникальных посетителей и других связанных метриках с помощью анализа видеоряда с камер наблюдения.
Традиционные методы
Возможно, вы замечали при входе в торговый центр человека, который отмечает посетителей на листочке. Можно только догадываться, что происходит дальше. Вероятно, листочки со всех входов сводятся в один список и данные суммируются. У такого решения можно отметить несколько крупных недостатков:
- невысокая точность - не учитывается уникальность посетителей: например, когда один и тот же человек прошел через несколько входов, возможны и человеческие ошибки при вводе данных;
- не масштабируется - для каждого входа в магазин нужен отдельный человек, что приводит к росту расходов на оплату труда;
- неполное - измерение и анализ дополнительных атрибутов будет кратно увеличивать трудоемкость.
Здесь расскажу о том, как мы решали проблему подсчета уникальных посетителей на торговой точке с использованием компьютерного зрения и алгоритмов глубокого обучения.
Этапы разработки
Постановка задачи
Цель заказчика – посчитать количество посетителей точки продаж и сколько из них конвертируется в покупателей. Также заказчик хотел понять, в какое время дня и недели загруженность достигает пика, узнать среднее время обслуживания одного покупателя и сделать демографический срез.
Таким образом, мы декомпозировали проект на 4 задачи:
- Найти лица на видео.
- Распознать лица, чтобы измерить их схожесть друг с другом.
- Кластеризовать лица по схожести и подсчитать кластеры, т.е. уникальных посетителей.
- Проанализировать время посещений, длительность обслуживания, пол и возраст покупателей.
Дальше немного подробнее про каждый этап.
1. Детекция лиц
Задача номер один – найти все лица на видеопотоке. Для этого запускаем алгоритм детекции лиц, вырезаем их и сохраняем для дальнейшей обработки. В результате получаем большое количество изображений, но пока не знаем, какие из них относятся к одним и тем же людям:

Для улучшения качества распознавания лиц на следующем шаге целесообразно отфильтровать изображения низкого качества, например:
- Выбрать изображения определенной высоты и ширины. Таким образом, мы будем анализировать людей, которые находятся в интересующей нас зоне поиска. Нижние и верхние пороги вычисляем эмпирически;
- Отсеить нефронтальные и перекрытые лица, так как алгоритм распознавания лиц точнее определяет схожесть, когда есть полное изображение лица;
- Удалить размытые изображения, которые часто встречаются на потоках видео с камер без высокой четкости.
Вот так выглядят нефронтальные изображения лиц, которые мы вычисляем на основании расположения ключевых точек: нос, рот и глаза:

2. Распознавание лиц
На этом этапе мы должны создать векторные представления лиц с помощью моделей распознавания, в точности как в задаче идентификации по лицу. Это необходимо, чтобы сравнить схожесть лиц попарно, как на картинке ниже (лица одного и того же человека будут иметь низкие значения):

В некоторых случаях алгоритм распознавания лиц нужно обучать на изображениях, совпадающих с качеством камеры. Камеры наблюдения в магазинах обычно записывают видео с невысоким разрешением. Если обучать алгоритм по фотографиям высокой четкости, то на изображениях низкого качества модели будут совершать множество ошибок.
3. Кластеризация лиц
Теперь обучаем несколько алгоритмов кластеризации на полученных векторах с предыдущего шага и выбираем наиболее подходящий в зависимости от ограничений по вычислительным ресурсам, времени на обработку и точности.
Мы не можем знать заранее, сколько человек собираются посетить нашу торговую точку. Поэтому подбираем методы, которые сами умеют определять количество кластеров. Помимо кластеризации проводим дополнительную пост-обработку: объединяем близкие кластеры и разделяем кластеры с низким значением внутренней схожести.

Финальное количество кластеров будет равно количеству уникальных посетителей, а в каждом кластере будут представлены лица одного и того же человека.
4. Дополнительная аналитика
Если сгруппировать изображения людей в кластеры, то не составит большого труда рассчитать время и длительность посещений.
Для проведения демографического анализа потребуется обучение дополнительных алгоритмов распознавания пола и возраста. Далее мы применим эти алгоритмы для каждого кластера лиц и выберем наиболее частые значения для максимизации точности.
| Распознавание возраста в группы 15-20, 25-35 или 40-50 лет | Определение пола (m - мужской, f - женский ) |
|---|---|
 |
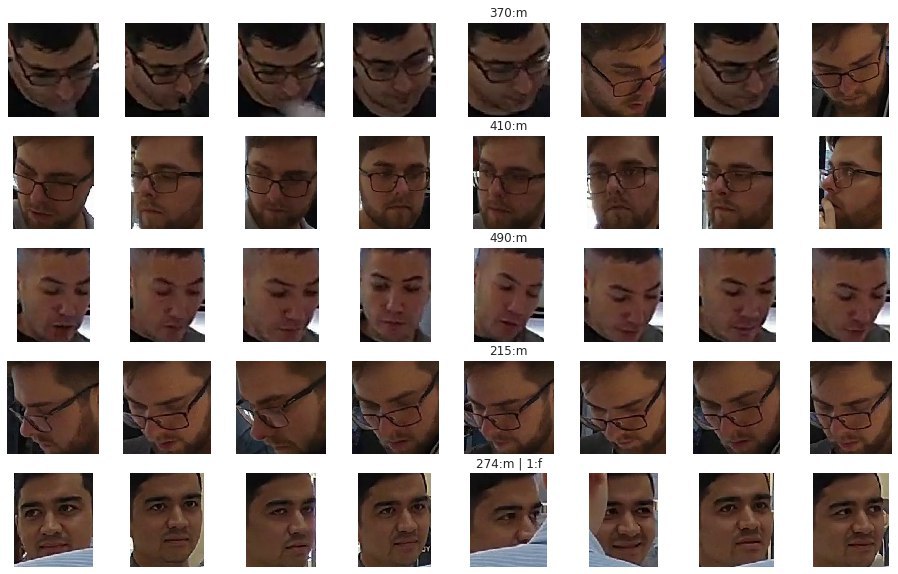 |
Результаты
Качество видеосъемки ниже, чем на фотографиях. Поэтому добиться результатов высокой точности достаточно сложно. Однако описанный подход способен решить задачу на приемлемом уровне. Полученные результаты можно применять в системах, не требующих медицинской точности или в качестве пред-обработки данных для визуальной верификации человеком. Также мы выяснили: при работе с потоком видео критическую роль играет подготовка данных для моделей. Чем меньше мусора мы подавали на вход, тем меньше ошибок получали на выходе.