Завершился второй раунд соревнования по кластеризации данных от Telegram. На хакатоне предлагалось разработать алгоритмы для группировки новостей на русском и английском языках в сюжеты и категории. Здесь я опишу наш подход к решению поставленных задач.
Задача
Цель конкурса – создание агрегатора новостей. Telegram предоставил множество статей из разных источников, написанных на десятках языках. На первом этапе организатор предложил разработать пять алгоритмов:
- Как определить язык и выделить только русские и английские статьи.
- Как экстрагировать новости от аналитических статей.
- Как классифицировать новости на семь категорий: общество, спорт, технологии, экономика, развлечения, наука и другие.
- Как сгруппировать схожие новости в сюжеты.
- Как проранжировать сюжеты от наиболее важных к менее важным.
На втором этапе необходимо было поднять http-сервер для индексация новых статей и вывода результатов.
Большое внимание уделялось не только точности алгоритмов, но и скорости обработки большого количества статей, что отразилось на выборе алгоритмов.
Решение
1. Определение языка
Чтобы определить язык новости не нужно было обучать собственную модель, так как можно найти пред-обученные модели с высокой точностью. После оценки нескольких алгоритмов наш выбор пал на fasttext, который показывал точность на уровне 99.5% и скорость 30 миллисекунд на 1000 статей.
| Сегмент текста | Точность | Скорость |
|---|---|---|
| Заголовок | 99.16% | 14мс/1000 |
| Заголовок + анонс | 99.45% | 30мс/1000 |
| Полный текст статьи | 99.32% | 218мс/1000 |
2. Экстрагирование новостей от аналитических статей
На этом шаге мы решили разметить собственный небольшой набор данных для выбора финального алгоритма. Для обучения мы использовали доступные датасеты с новостями и блогами. Учитывая необходимость высокой скорости, нам было важно определять новости только по заголовкам и без использования тяжелых моделей.
Таким образом, мы протестировали несколько подходов с представлением текста (мешок слов, Tf-Idf и просто частота использования частей речи) и обучением легковесных моделей байесовским методом, логистической регресией и линейный SVM. Выбранные модели представлены в таблице:
| Язык | Сегмент текста | Пред-обработка текста | Векторное представление | Алгоритм | Точность | Скорость |
|---|---|---|---|---|---|---|
| русский | заголовок | части речи | частота использования | Logistic Regression | 89% | 2мс/1000 |
| английский | заголовок | - | tf-idf | Complement Naive Bayes | 72% | <1мс/1000 |
Одни и те же методы показывают меньшую точность на английском языке. Возможно, это исходит из неоднозначности заголовков, которые часто не дают четкого представления о содержании текста. Примеры определения новостей по заголовкам:
| Примеры новостей | Примеры не новостей |
|---|---|
 |
 |
 |
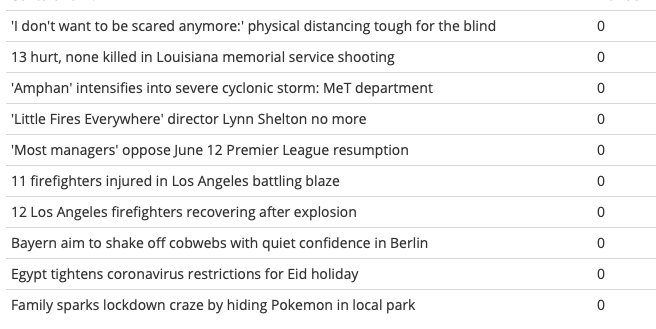 |
3. Классификация по жанрам
Как и в случае с новостями мы использовали собственную разметку для выбора алгоритма и внешние наборы данных для обучения. Не во всех внешних источниках категории совпадали с целевыми для соревнования, поэтому пришлось дополнительно потрудиться над исправлением разметки категорий.
Для классификации категорий уже недостаточно было использовать только заголовки, поэтому мы векторизовали весь текст статьи. Для увеличения точности мы произвели нормализацию слов (лемматизация), чтобы, к примеру, слова “красивые” и “красивая” имели одно значние “красивый”. Обучали те же самые классификаторы, как и на предыдущем шаге. Лучшие модели:
| Язык | Сегмент текста | Пред-обработка текста | Векторное представление | Алгоритм | Точность | Скорость |
|---|---|---|---|---|---|---|
| русский | полный текст | лемматизация | tf-idf | Logistic Regression | 86% | 29мс/1000 |
| английский | заголовок | лемматизация | tf-idf | Logistic Regression | 75% | 33мс/1000 |
Снова результаты на английском языке заметно хуже. Возможно это связано с тем, что статьи на английском языке часто относятся более чем к одной категории, и модель ошибается чаще. Примеры наиболее значимых слов для каждой категории:
| Категории на русском | Категории на английском |
|---|---|
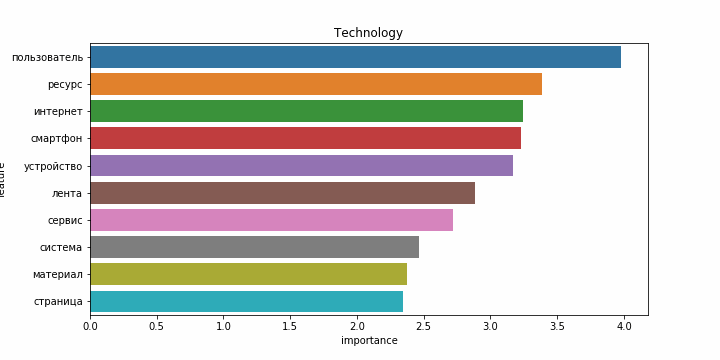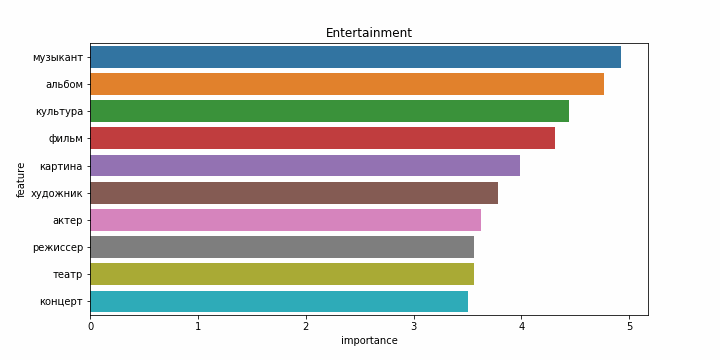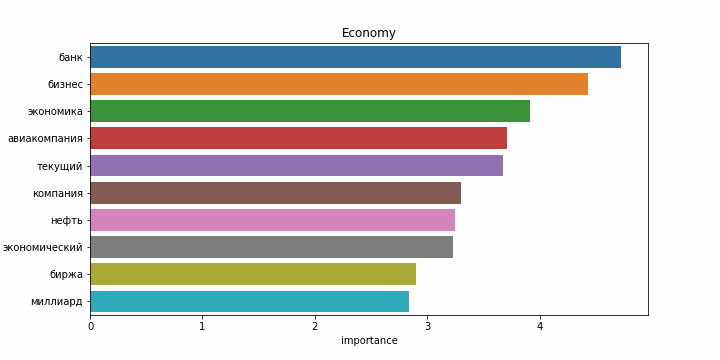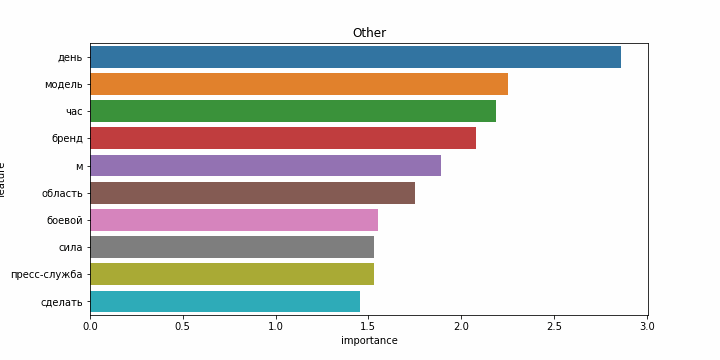 |
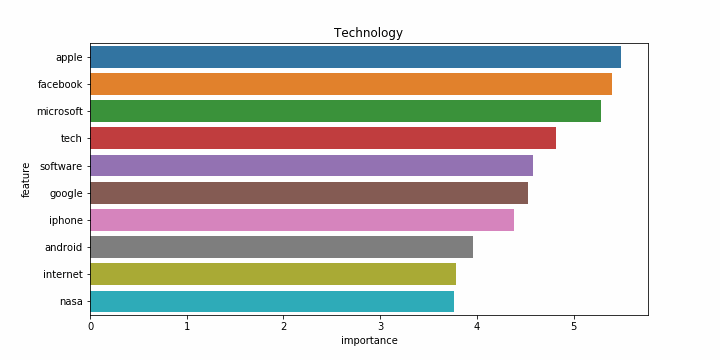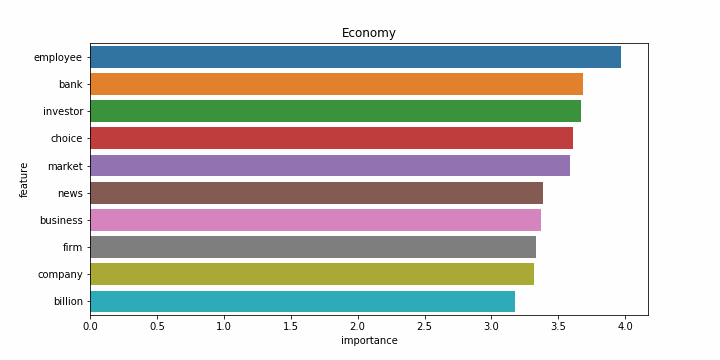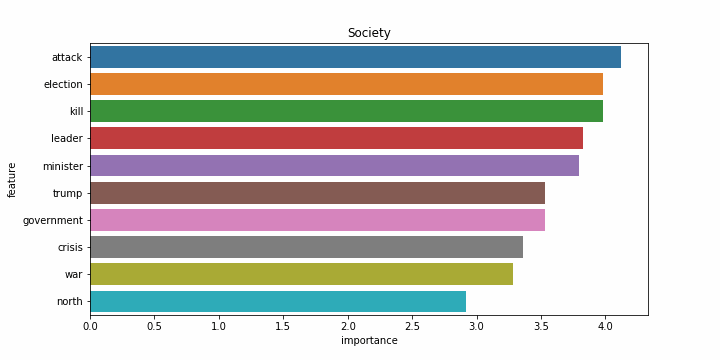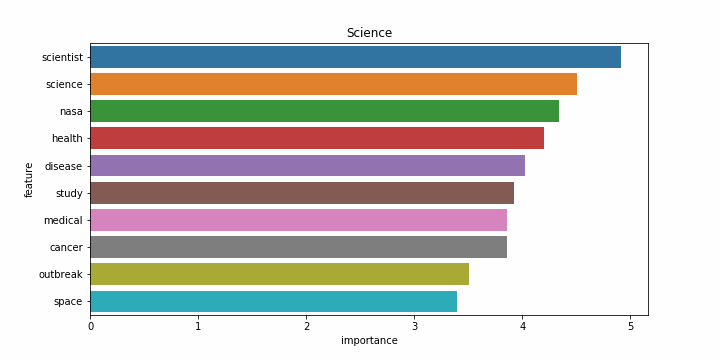 |
4. Группировка новостей в сюжеты
В отличии от классификации на категории или отделения новостей от других жанров, для кластеризации новостей в сюжеты невозможно обучить модели заранее. Это связано с тем, что каждый день мы видим новые темы в новостях. Точность объединения новостей в сюжеты могла быть достигнута только в случае кластеризации новостей “на лету”, то есть во время обработки большого массива статей за короткий промежуток времени.
Как и в случае с классификацией категорий, мы использовали векторное представление. Далее относили каждую новость в отдельную группу, а с помощью алгоритма иерархической кластеризации последовательно объединяли маленькие группы в большие, начиная с самых схожих по составу слов. Процесс останавливается при отсутствии достаточно схожих групп.
| Пример результатов кластеризации |
|---|
 |
 |
5. Ранжирование сюжетов
Далее было необходимо проранжировать сюжеты, чтобы наиболее важные темы отражались первыми. Задачу нетривиально решать с помощью машинного обучения, потому что важность новостей - достаточно субъективная оценка, которая будет отличаться для людей с разными интересами, из разных регионов или в разные дни недели.
При решении этой задачи мы положились на довольно распространный метод RFM (Recency, Frequency, Monetary), используемый для оценки клиентской аудитории:
- В качестве Recency мы использовали среднюю схожесть новостей внутри сюжета, отдавая больший приоритет наиболее связанным сюжетам;
- Frequency - количество статей в сюжете, очевидно, что о важных событиях пишут чаще;
- а для Monetary мы оценивали количество источников, которые пишут о каком-то событии: чем больше источников пишут на ту или иную тему, тем больший вес у сюжета.
| Результаты сортировки сюжетов |
|---|
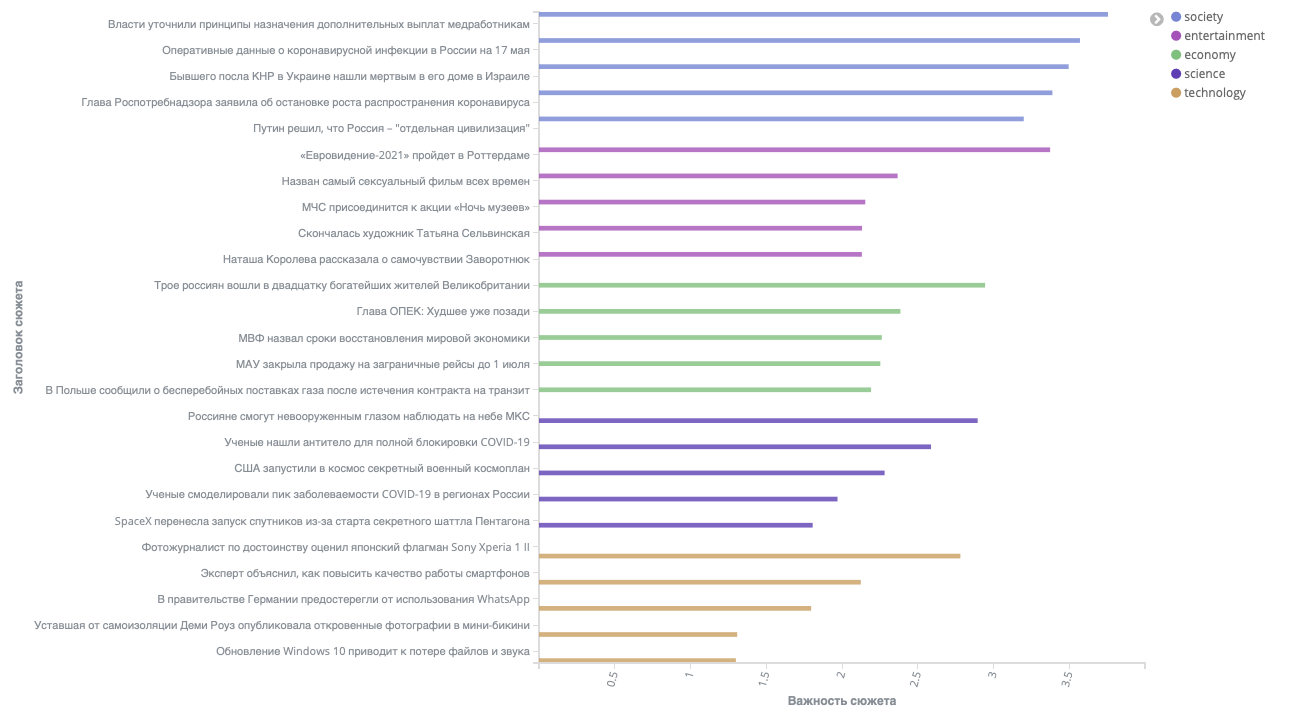 |
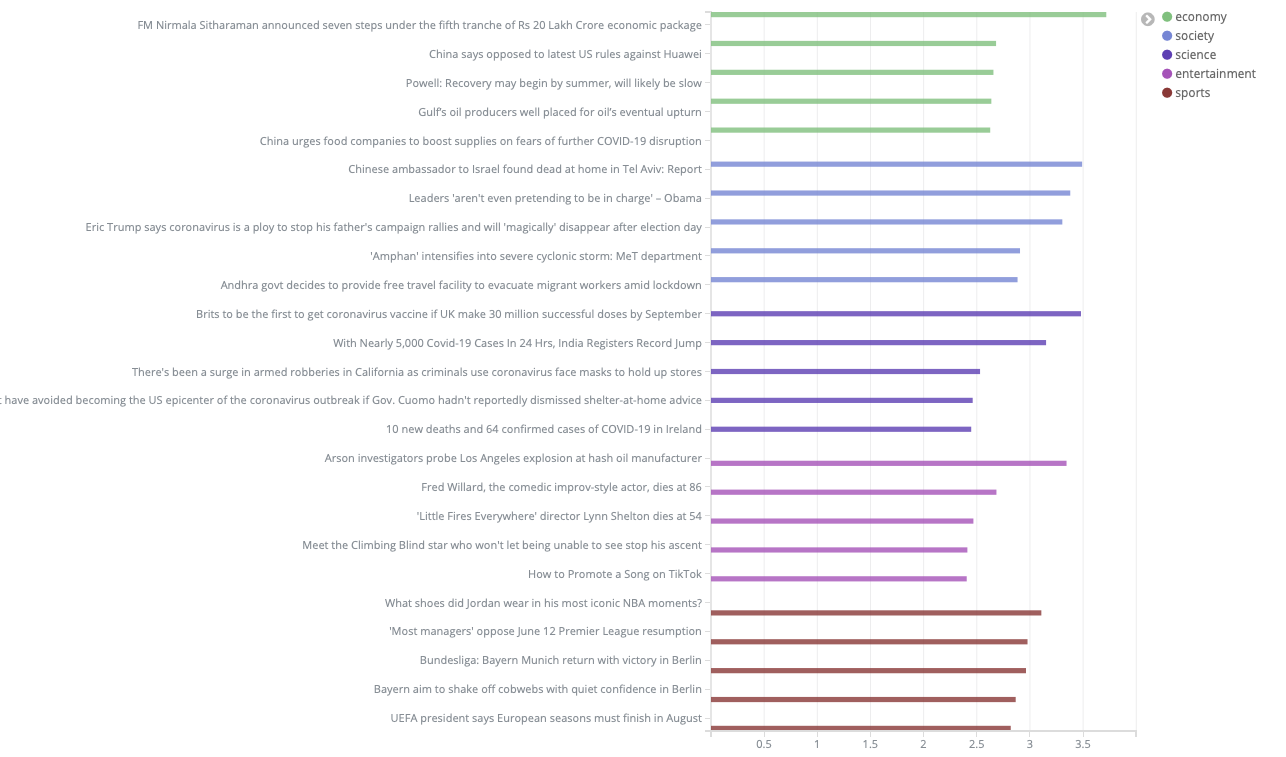 |
Заключение
Пока мы ждем результатов хакатона, хочется отметить, – большинство задач решались достаточно простыми, но действенными методами. Использованные алгоритмы векторизации и классификации текста существуют уже не один десяток лет и при этом дают высокую скорость и приемлемый уровень точности. Для других сценариев применения этих моделей возможно использование более сложных алгоритмов для достижения еще большей точности.
Обновление от 24 июня 2020 г.
Результаты алгоритма доступны на сайте хакатона. Можно посмотреть сюжеты новостей на английском и русском языках или по категориям.
Ссылки на датасеты
- русские новости
- английкие новости: bbc, uci агрегатор
- английские блоги